网络爬虫是一种自动化程序linux之家,可以模拟人类的浏览器行为linux网络爬虫,自动地访问、抓取互联网上的数据。在大数据时代,网络爬虫已经成为了各行各业不可或缺的工具之一。本文将带你深入了解Linux网络爬虫的相关知识,从入门到精通。
1.网络爬虫的基本概念
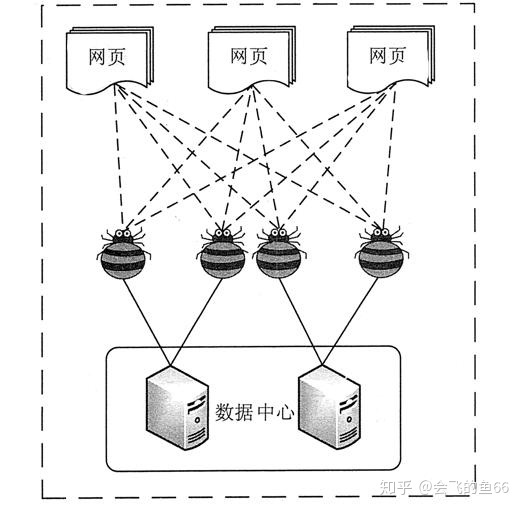
网络爬虫是一种自动化程序,可以模拟人类的浏览器行为,自动地访问、抓取互联网上的数据。它可以自动化地获取和处理大量的数据,并将其保存在数据库中。这些数据可以用于各种分析、统计和挖掘应用,如搜索引擎、商品价格比较、舆情监测等。
2. Linux网络爬虫的优势
Linux是一种开源操作系统,具有安全、稳定和高效等特点。与Windows相比,Linux更适合作为服务器系统运行。因此,在进行大规模数据采集时,使用Linux系统作为爬虫主机是非常明智的选择。
3. Python语言在网络爬虫中的应用
Python是一种简单易学、功能强大、开发效率高的编程语言,非常适合用于网络爬虫开发。Python有丰富的网络爬虫库和框架,如BeautifulSoup、Scrapy等,可以帮助我们轻松地实现各种爬虫任务。
4.网络爬虫的基本流程
网络爬虫的基本流程包括获取页面、解析页面、抽取数据、存储数据等步骤。在获取页面时linux内核,我们可以使用HTTP协议模拟浏览器请求。在解析页面时,我们可以使用正则表达式或XPath等方式进行数据抽取。在存储数据时,我们可以选择将数据保存到文件或数据库中。
5.网络爬虫的反爬机制与应对策略
为了防止网络爬虫对网站造成过大的压力和影响,许多网站都设置了反爬机制。这些机制包括IP封禁、验证码、动态页面等。为了应对这些反爬机制linux网络爬虫,我们需要采取一系列策略,如使用代理IP、分布式爬虫等。
6.爬虫数据的清洗和分析

在进行大规模数据采集后,我们需要对数据进行清洗和分析。清洗可以帮助我们去除重复数据、格式化数据等。分析可以帮助我们发现数据之间的关系、进行可视化等,从而更好地理解数据背后的含义。
7.网络爬虫的应用案例
网络爬虫已经被广泛应用于各个领域,如搜索引擎、舆情监测、商品价格比较等。在本文中,我们将介绍一个实际的网络爬虫应用案例:使用网络爬虫抓取天猫商城上的商品信息,并进行价格比较和分析。
8.网络爬虫开发中的注意事项
在进行网络爬虫开发时,我们需要遵守一些规范和注意事项。如不要过度访问同一网站、不要过度依赖单一数据源、遵守网站的robots协议等。同时,我们还需要注意代码的可维护性和可扩展性,以便在后期维护和扩展时更加方便。
本文简要介绍了Linux网络爬虫的相关知识,从基本概念到应用案例,详细阐述了网络爬虫开发中的各个方面。希望本文能够对想要学习或进一步深入了解网络爬虫的读者有所帮助。





