重新梳理问题解决思路:
一、判断终端显示编码和linux字符集是否统一。不统一的话终端显示的命令全部都是乱码,比如vim打开可编辑文件时 终端显示的就是乱码
1.1 linux字符集
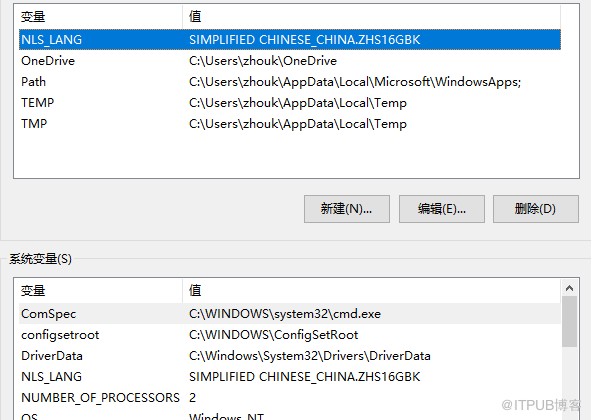
echo $LANG 判断linux字符集
临时修改命令 比如:export LANG=zh_CN.gb2312
永久修改命令
vim /etc/sysconfig/i18n
LANG="zh_CN.UTF-8"
source /etc/sysconfig/i18n
1.2 检查终端连接工具的编码
不同工具设置位置不同,找找总会找到的
让上述两者保持一致,保证终端的命令显示无乱码
二、vim打开文件时,文件中的中文存在乱码
此时是vim的编码和默认对文件的解码不一致导致的
2.1 更改vim配置文件
首先第一步找到VIM的配置文件
windows中的vim的配置文件是: C:Program FilesVim_vimrc
linux的vim配置文件: vi ~/.vimrc
接着修改这个文本文档,文档前面的所有内容均不需要动linux 终端 中文乱码,只要把下面这些代码加入到最后即可。
set encoding=utf-8
set termencoding=utf-8
set fileencoding=utf-8

set fileencodings=ucs-bom,utf-8,cp936,gb18030
set imcmdline
source $VIMRUNTIME/delmenu.vim
source $VIMRUNTIME/menu.vim
尤其要注意,最后的两行代码,千万不能放到配置文件的上面。
2.2 检查文件编码
首先要明确:Windows中默认的文件格式是GBK(gb2312),而Linux一般都是UTF-8。在vim中查看文件的编码方式:set fileencoding ,即可显示文件编码格式,如果什么都没有显示,请看第三点。如果你只是想查看其它编码格式的文件或者想解决用Vim查看文件乱码的问题,那么你可以在~/.vimrc (如果是windows系统,那么应该修改_vimrc)文件中添加以下内容:
set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936
source ~/.vimrc 生效配置
这样,就可以让vim自动识别文件编码(可以自动识别UTF-8或者GBK编 码的文件),其实就是依照fileencodings提供的编码列表尝试,如果没有找到合适的编码,就用latin-1(ASCII)编码打开。
可能存在文件是gbk编码的linux社区,但是vim识别成了utf-8因此也会导致乱码,此时建议用第4点指定编码格式打开以指定的编码打开某文件,如打开windows中以ANSI保存的文件:
vim file.txt -c "e ++enc=GB18030"文件编码转换,在Vim中直接进行转换文件编码,比如将一个文件转换成utf-8格式:
:set fileencoding=utf-8
6.如果已经打开了解码错的文件,想重新设置编码格式:

:edit ++enc=utf8查看文件格式
:set fileformat?设置文件格式为 unix
:set fileformat=unix
2.3 vim的配置说明
Vim 有四个跟字符编码方式有关的选项,encoding、fileencoding、fileencodings、termencoding (这些选项可能的取值请参考 Vim 在线帮助 :help encoding-names),它们的意义如下:
2.4 vim原理
Vim 启动,根据 .vimrc 中设置的 encoding 的值来设置 buffer、菜单文本、消息文的字符编码方式。读取需要编辑的文件,根据 fileencodings 中列出的字符编码方式逐一探测该文件编码方式。并设置 fileencoding 为探测到的,看起来是正确的 (注1) 字符编码方式。对比 fileencoding 和 encoding 的值,若不同则调用 iconv 将文件内容转换为encoding 所描述的字符编码方式,并且把转换后的内容放到为此文件开辟的 buffer 里,此时我们就可以开始编辑这个文件了。注意,完成这一步动作需要调用外部的 iconv.dll(注2),你需要保证这个文件存在于 $VIMRUNTIME 或者其他列在 PATH 环境变量中的目录里。编辑完成后保存文件时linux 终端 中文乱码,再次对比 fileencoding 和 encoding 的值。若不同,再次调用 iconv 将即将保存的 buffer 中的文本转换为 fileencoding 所描述的字符编码方式,并保存到指定的文件中。同样,这需要调用 iconv.dll由于 Unicode 能够包含几乎所有的语言的字符,而且 Unicode 的 UTF-8 编码方式又是非常具有性价比的编码方式 (空间消耗比 UCS-2 小),因此建议 encoding 的值设置为utf-8。这么做的另一个理由是 encoding 设置为 utf-8 时,Vim 自动探测文件的编码方式会更准确 (或许这个理由才是主要的 ;)。我们在中文 Windows 里编辑的文件,为了兼顾与其他软件的兼容性suse linux 下载,文件编码还是设置为 GB2312/GBK 比较合适,因此 fileencoding 建议设置为 chinese (chinese 是个别名,在 Unix 里表示 gb2312,在 Windows 里表示cp936,也就是 GBK 的代码页)。
部分内容参考:linux各种中文乱码解决办法整理 - Avatarx - 博客园





